
Introduction
Have you ever asked Google to wake you up tomorrow at 7 a.m? Or how old is Madonna? In both cases, you can thank Natural Language Processing for your machine’s ability to understand and process words, and sequentially give you an answer. Natural Language Processing or NLP for short is a subfield of Computer Science and Artificial Intelligence that deals with processing and analyzing large amounts of raw language data. It is easy for us to understand a language, our natural language, however, for a computer this represents an impossible task, unless we “translate” our natural language to the language a computer can understand. Natural Language Processing uses various techniques in order to create structure out of language data, and for that we use different toolkits and libraries.
The goal of this post is to guide you through the basic steps of using spaCy and its functionalities with code examples, and useful definitions. I recommend having at least basic knowledge of the Python programming language before diving into this post, as spaCy is a Python library.
Common NLP Tasks and Use Cases
The most common general use cases of NLP are:
- Voice recognition
- Translation, autocomplete, and autocorrect
- Analyzing sentiment of customer reviews, classifying e-mails as spam vs. legitimate
- Chatbots
- Automatic text summarization
NLP has also a variety of use cases in the healthcare, finance, retail and e-commerce, and cybersecurity.
The most common NLP tasks include tokenization, lemmatization, stop words, tagging parts of speech, and word frequency. In this post, I will define and describe these common tasks, as well as provide an example using spaCy.
What is spaCy?
spaCy is an open-source software library for Natural Language Processing, written in Python. It was created back in 2015, and since then it has become widely used for NLP tasks. It is fast and efficient, and it uses the latest state-of-the-art approaches. spaCy helps us process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems, or to pre-process text for deep learning.
Installing spaCy is fairly easy, and it depends on which operating system you use. Currently, the latest version of spaCy is 3.2, check out their website for installation instructions.
Using spaCy
In order to use spaCy, first we need to import it, and load the language model we want to use as an instance (in this case the language model is English). This instance is commonly named nlp:
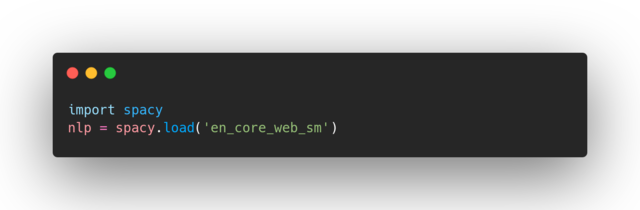
‘en-core-web-sm’ is the English language model. The next step is to create a container for accessing linguistic annotations, called Doc. This step converts the given example text to a structure that spaCy can understand:

And that is it. Now you can use various spaCy functionalities to discover details about this text, and analyze it. Keep in mind you will need to create the Doc container for every text you want to analyze.
Reading strings and sentences
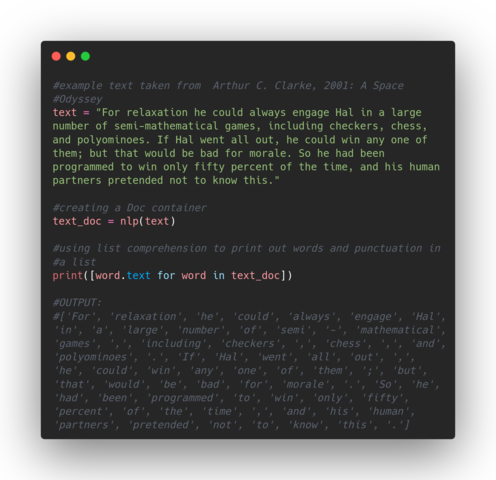
The most basic functionality of spaCy is reading strings and sentences from a selected text. The first example shows how to print a separated list of words and punctuation from an example text. Notice how spaCy separates all the punctuation from words:
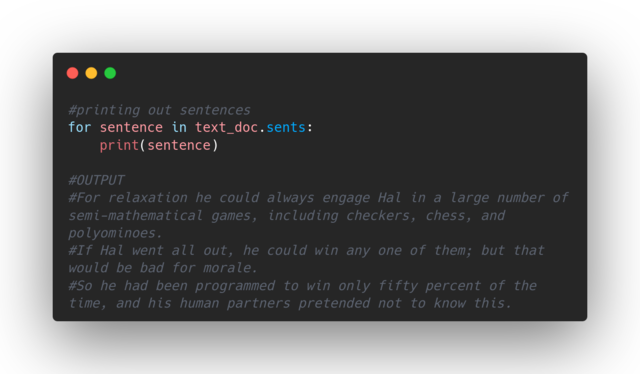
And what about sentences? spaCy is smart enough to know where a sentence starts and where it ends, here is an example:
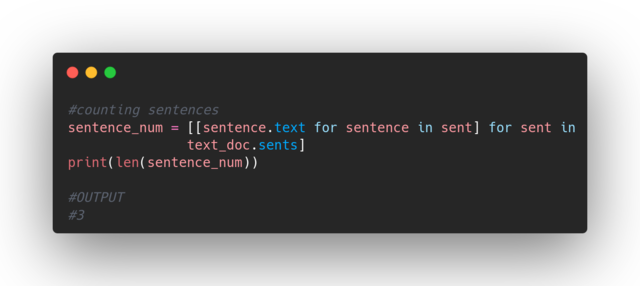
We can also count how many sentences are there in a given text. I am using a simple list comprehension to do this, but you can also use a for loop:
Tokenization
Tokenization is the process of splitting up a sequence of characters, or a document unit, into pieces called tokens. A token is an instance of a sequence of characters that are part of a greater unit like a text or a document, a basic building block of a Doc object in spaCy. You might find that sometimes tokens are referred to as words or terms, but it is important to make the distinction. So, how does tokenization work in spaCy?
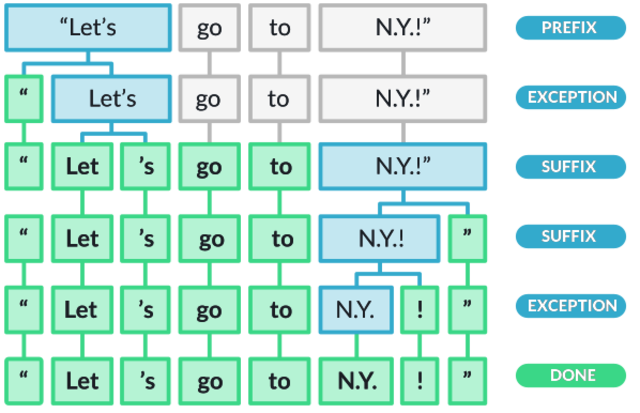
The very first step spaCy takes is to split the original document on whitespace. Then it moves on to separating the prefix characters from the beginning, then exceptions for splitting a string into several tokens (Let’s becomes Let — ‘s), and finally the suffixes which are characters at the end.
We have already mentioned tokenization in the previous section, but in terms of reading strings from a text. Let’s see another example:
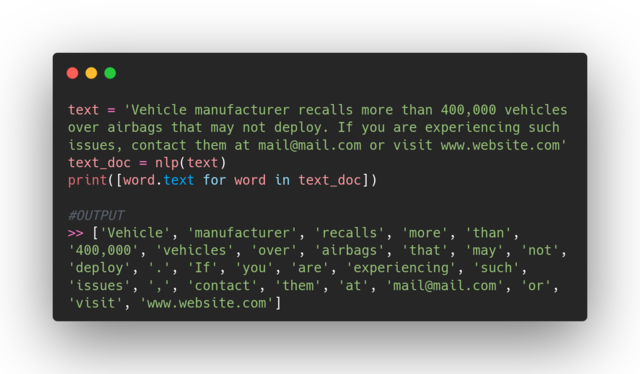
The interesting part is seeing how spaCy differentiates between punctuation in a website form, and it categorizes it as a single token, as well as an e-mail form.
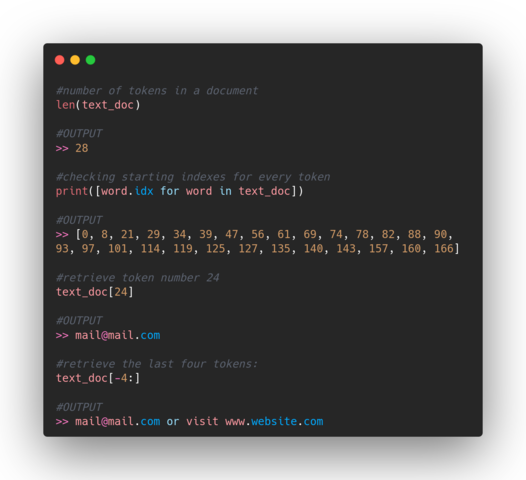
Another useful functionality for any analysis might be to count the number of tokens, and if necessary extract a specific token using their index:
Part of Speech Tagging (POS)
Parts of Speech Tagging is a process of identifying the role a particular word has in a text, based on its definition, as well as the context. There are 9 parts of speech in the English language: noun, verb, article, adjective, preposition, pronoun, adverb, conjunction, and interjection. However, there are subcategories of every part of speech — like the proper noun is part of the noun category. Identifying POS with spaCy is very easy, let’s see an example:
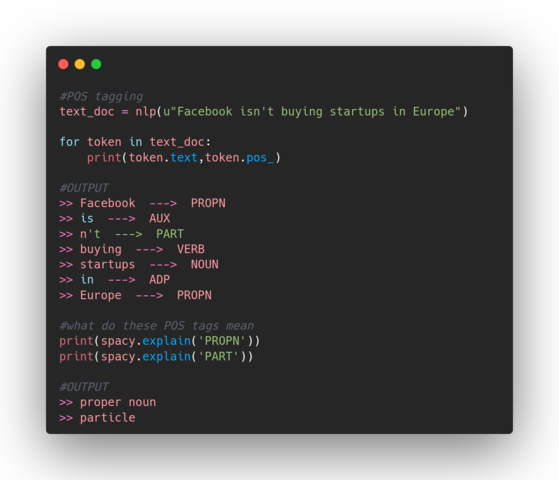
You can find more information about all parts of speech tags on spaCy.
Lemmatization
Lemmatization is a process of identifying a lemma of a word by applying morphological analysis, and the context in which the word is. A lemma represents a dictionary form of a word — it is a headword. Break, breaks, broke, broken and breaking are all forms of the word break which is their lemma. Let’s see a simple example using spaCy:
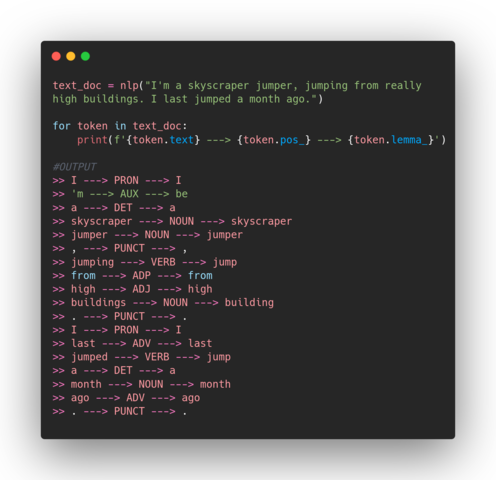
I used the word jump in several forms, twice as a verb jumped and jumping, and one time as a noun jumper. spaCy correctly identified their lemmas, and POS. In another example, I will show you how spaCy differentiates between two identical words, but with different meaning:
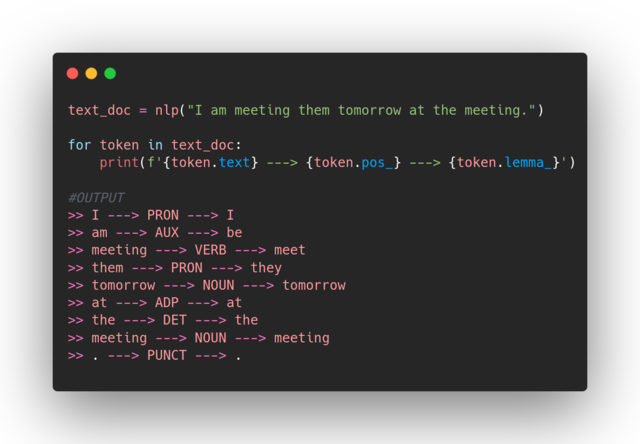
The word meeting has two meanings in this sentence, and spaCy again identified their lemmas correctly based on the context they were in.
Lemmatization is an essential process in NLP because it reduces words to their bases, and helps us analyze words as single items.
Stop Words
Stop words represent words that are highly frequent in a language, and as such are usually removed from a text that is being analyzed. There is no universal rule as to which words are deemed stop words, therefore, we are able to add words to the existing list. Let’s see how many stop words are in spaCy library:
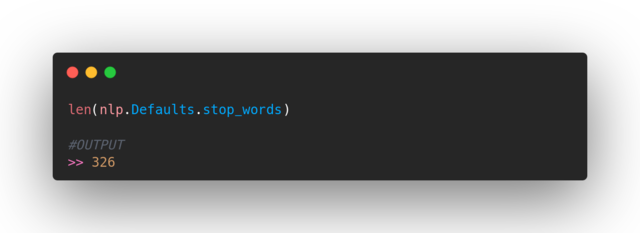
At this moment there are a total of 326 stop words in the list. Depending on a specific task we are performing, we can add, as well as remove stop words from this list.
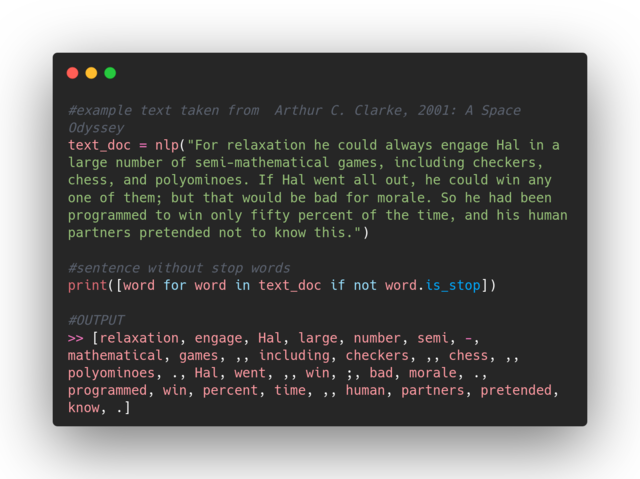
You can remove stop words from a text in a simple manner by using list comprehension:
Conclusion
As mentioned in this post, Natural Language Processing is a very large field of Computer Science, and we have only scratched the tiniest surface of it. We learned about basic and common processes in NLP using spaCy. I encourage you to not stop here, try it yourself, and explore even larger texts and documents using spaCy as an exercise. Examples I used in this post do not represent real-world scenarios where documents can be very large, and text preparation slower. Give it a go!